gym_connect4
This details the final project results for the Machine Learning Course CX 4240 at Georgia Tech.
For more background, check out the original proposal
You can also view the final presentation slides below:
Introduction
The goal of this project is to develop a bot using Reinforcement Learning that can play Connect 4 against humans.
Motivation
Reinforcement learning has recently been at the forefront of machine learning and applied to a wide variety of situations ranging from playing classical video games and beating professionals in board games [1, 2] to improving elevator performance [3]. Though not within the scope of this class, we believe reinforcement learning to be a good topic to explore and learn about in addition to the classical machine learning methods covered in class.
Installation
If you are interested in running the algorithm yourself, make sure to do the following (preferably in some Python environment):
- Clone the git repostiory
- Set up and install OpenAI Gym
- Set up and install keras-rl
- Install the Connect 4 enviornment. Run
pip install -e gym_connect4from the root of the repository
To run the training, modify train.py to point to the right files and use the policies and algorithms you want. Then you just run python train.py.
To play against your bot, modify train.py so that you are only loading in the neural network weights, using the Connect4VsHuman-v0 environment, and running dqn.test(...) so that you don’t overwrite your files. Run python train.py to start playing against your bot.
Training and Model Architecture
Libraries and Tools
The following tools were used:
- OpenAI Gym: toolkit for developing and comparing reinforcement learning algorithms
- keras-rl: deep reinforcement learning algorithms for Keras that work with OpenAI Gym out of the box
Policies and Algorithms
Our work primarily focused on 2 algorithms:
In a nutshell, DQNs attempt to learn the value of being in a particular state and then take an action that will maximize the reward. The action that a DQN takes is determined by the policy is it trying to optimize. The deep in DQN is the application of neural networks on standard Q Learning. Using a neural network allows us greater flexibility in keeping track of a greater number of states (the neural network neurons) and reward in each state (the weight of each neuron). However, this is at the cost of stability in the algorithm.
Double DQNs attempt to solve a problem with overestimation in DQNs. Learning can get complicated if we are initialized with bad values (leading to bad/confusing learning). Therefore, Double DQNs use two networks: one to choose the best Q value, and the other to generate the Q values. This helps mitigate the issue where the same network could potentially get stuck taking poor actions due to unlucky initialization.
For a full explanation of these algorithms, please read either the wikipedia article or the original journal articles.
- DQN Journal Article 1 and DQN Journal Article 2 [4, 5]
- Double DQN Journal Article [6]
Our work primarily focused on 2 policies for each of the algorithms:
Epsilon Greedy and Max Boltzmann are both algorithms that determine how to pick the next action. A brief summary of each algorithm is provided below.
Epsilon Greedy picks the state with the highest payout with a certain probability (epsilon) and randomly (with equal probability) choose a state otherwise. In other words, it will always pick the state with the best value, and only sometimes explore other options. This is a more naive approach since there is no guarantee the values are a good representation of how good the state is, but it is a simple algorithm that we thought would be a good baseline for our work.
Max Boltzmann is similar to Epsilon Greedy, but instead of choosing randomly, it assigns probabilities based on the weights of the other states. Instead of randomly picking a state, it will pick states that have greater potential.
In both policies, the weights will be continously updated. Full details are provided in the links.
Training and Model Architecture
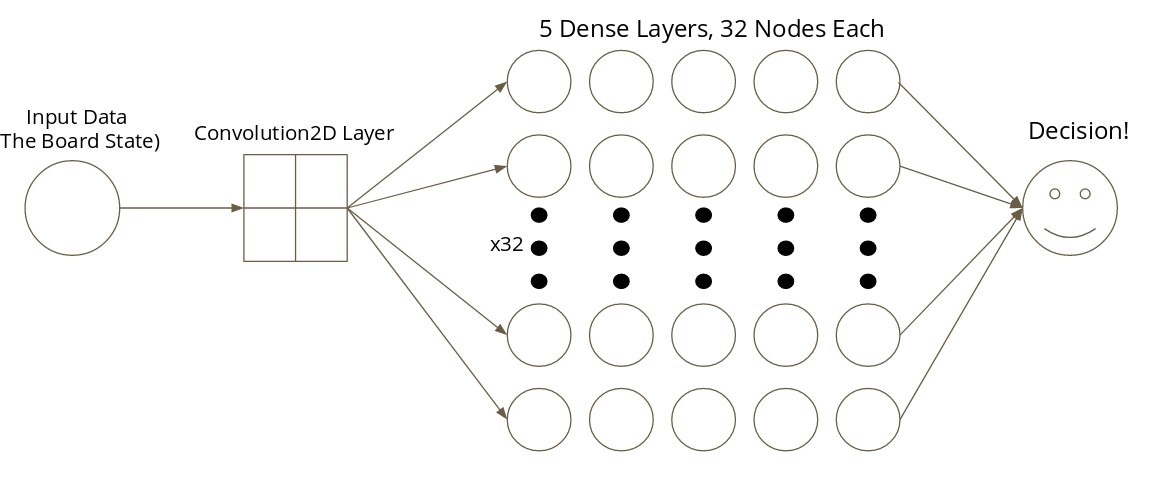
Since we are using DQN, it is necessary to create a neural network model. The neural network model consists of 1 3x3 convolutional layer, 5 Dense ReLu layers of 32 nodes each, and 1 Dense Linear layer of 7 nodes (representing the 7 decision in Connect 4). A diagram is shown below:
Generating our Dataset
Our dataset primarily consists of various random distributions and patterns that select actions. For training, we used the following patterns:
- 10% of moves were picked from a random uniform distribution
- 30% of moves were picked from various Dirichlet distributions
- 30% of moves were randomly chosen single column stacks
- 30% of moves were mimicking the last move the bot made
In addition, the opponent will always take a winning move and prevent a winning move whenever possible (e.g. 3 in a row). The reason we chose to use a variety of patterns is to give our AI more exposure to moves and strategies that could happen in an actual game. This helps round out the AI behavior to make it a better player.
Results
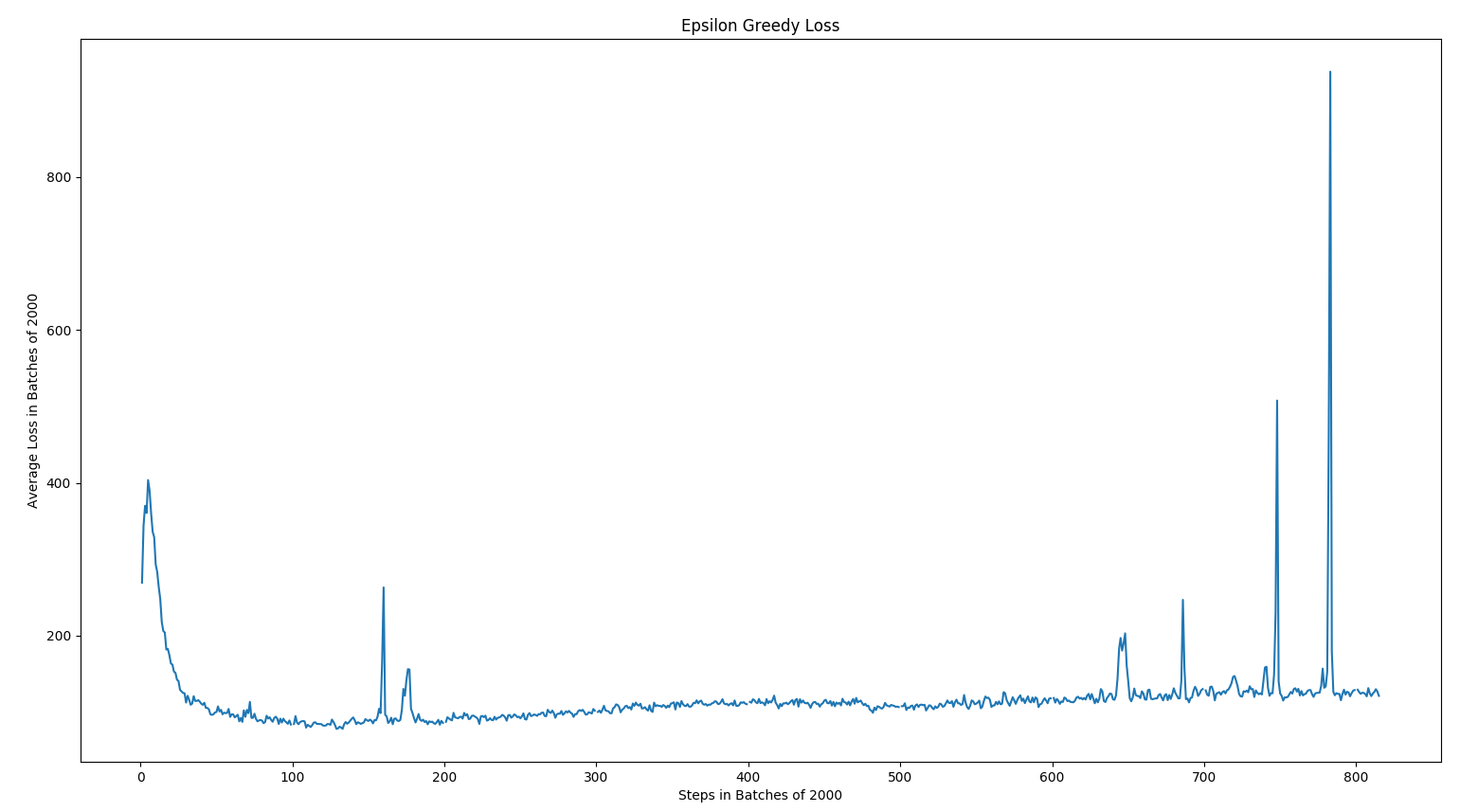
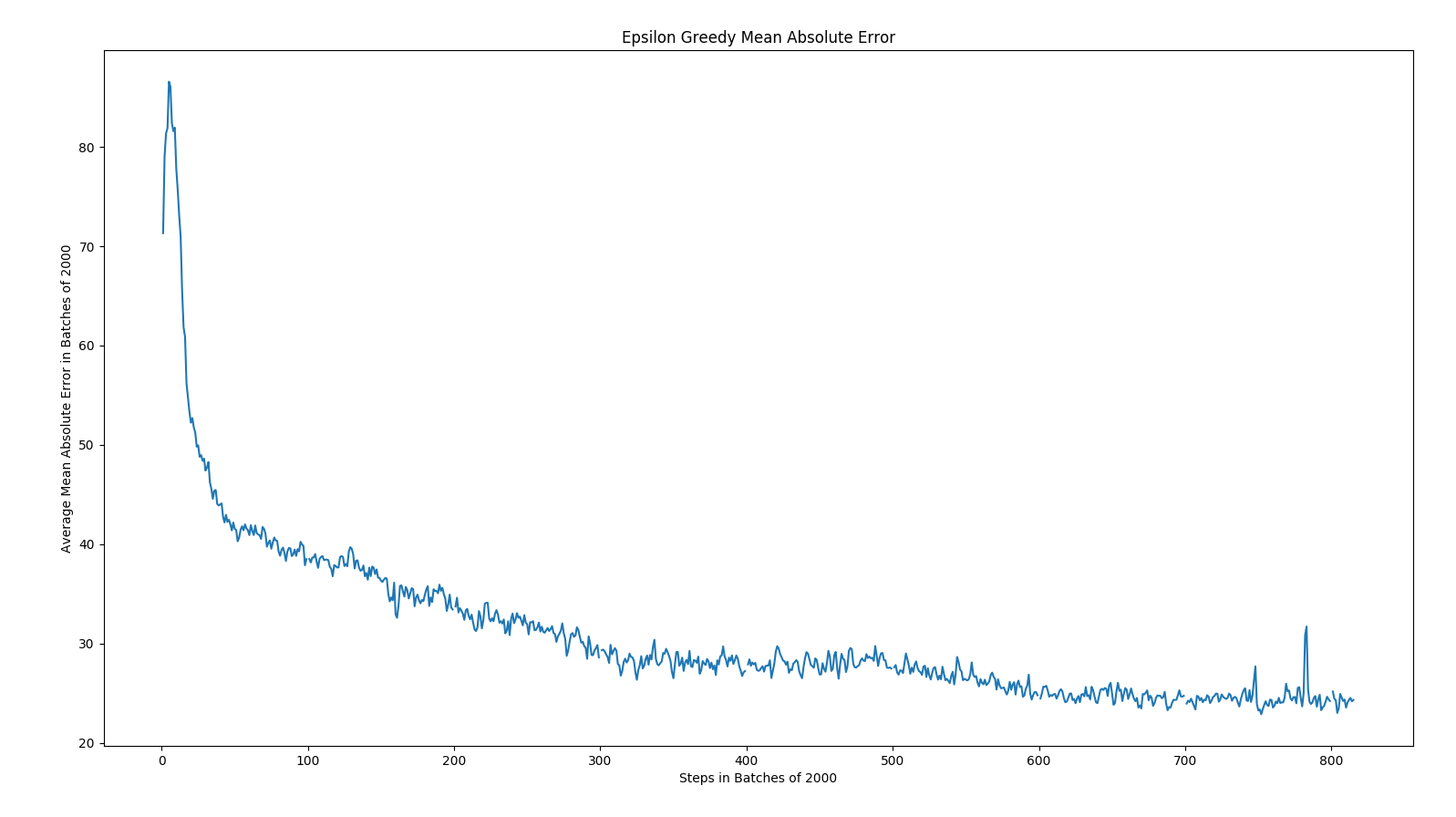
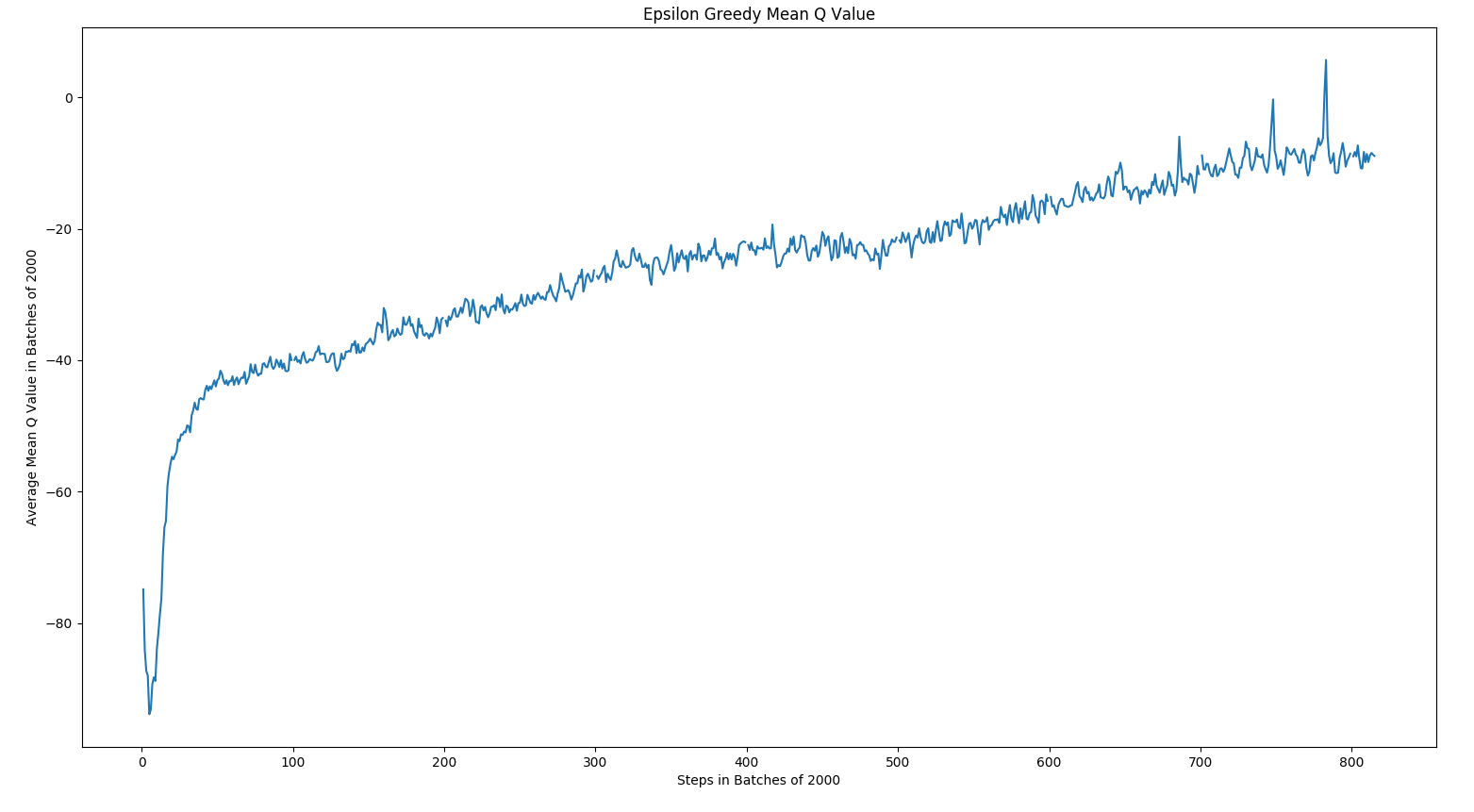
The following results are the loss, mean absolute error, and mean q values for Epsilon Greedy and Max Boltzmann policies for DQN.
As expected, the overall trend was that mean absolute error decreased over time, loss decreased over time, and the mean q values increased. In epsilon greedy, you can observe some spikes due to the changes in our opponents playing style. This leads us to believe that epsilon is less robust against new strategies than max boltzmann. Given how the algorithms work, this conclusion logically makes sense.
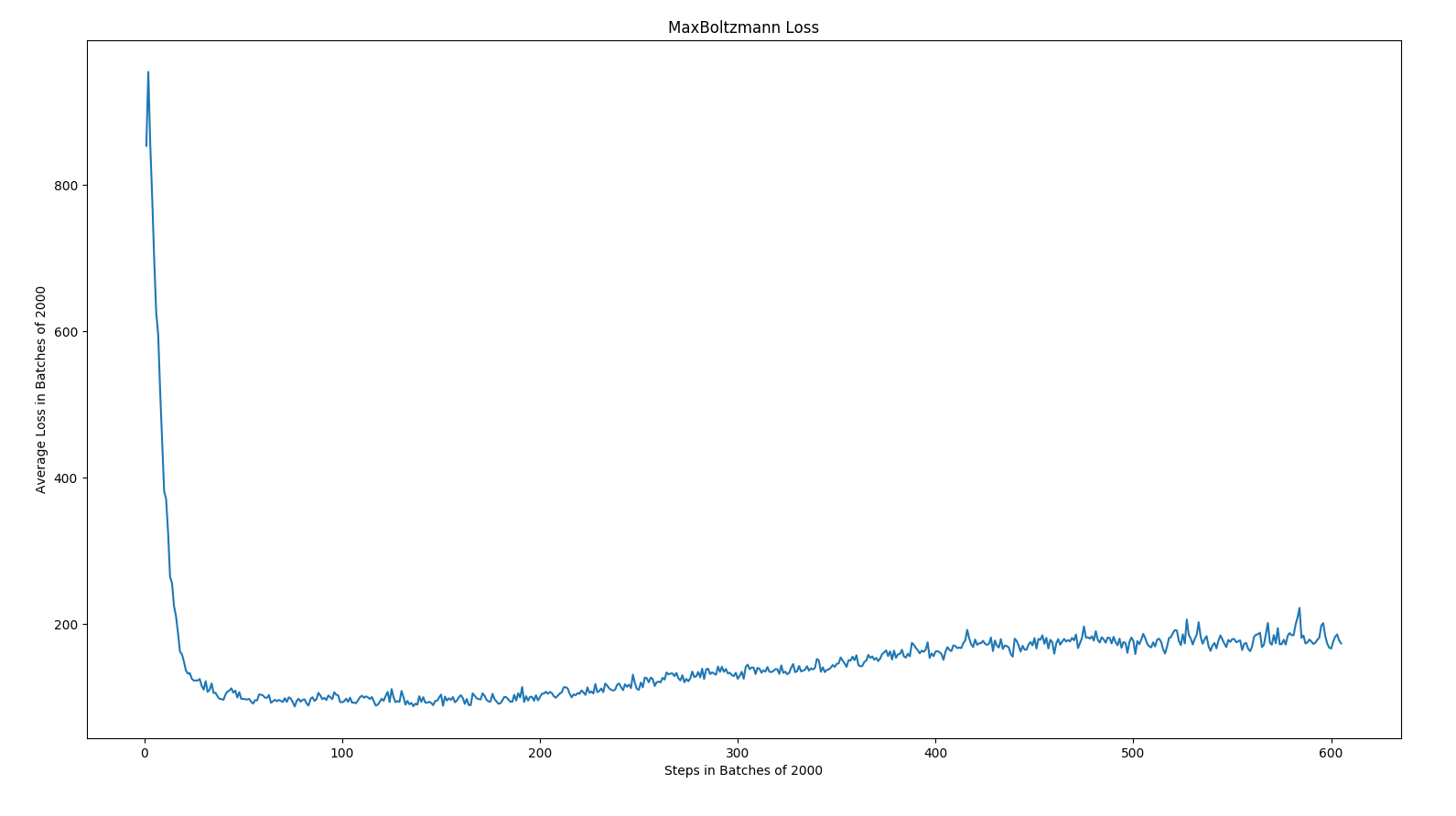
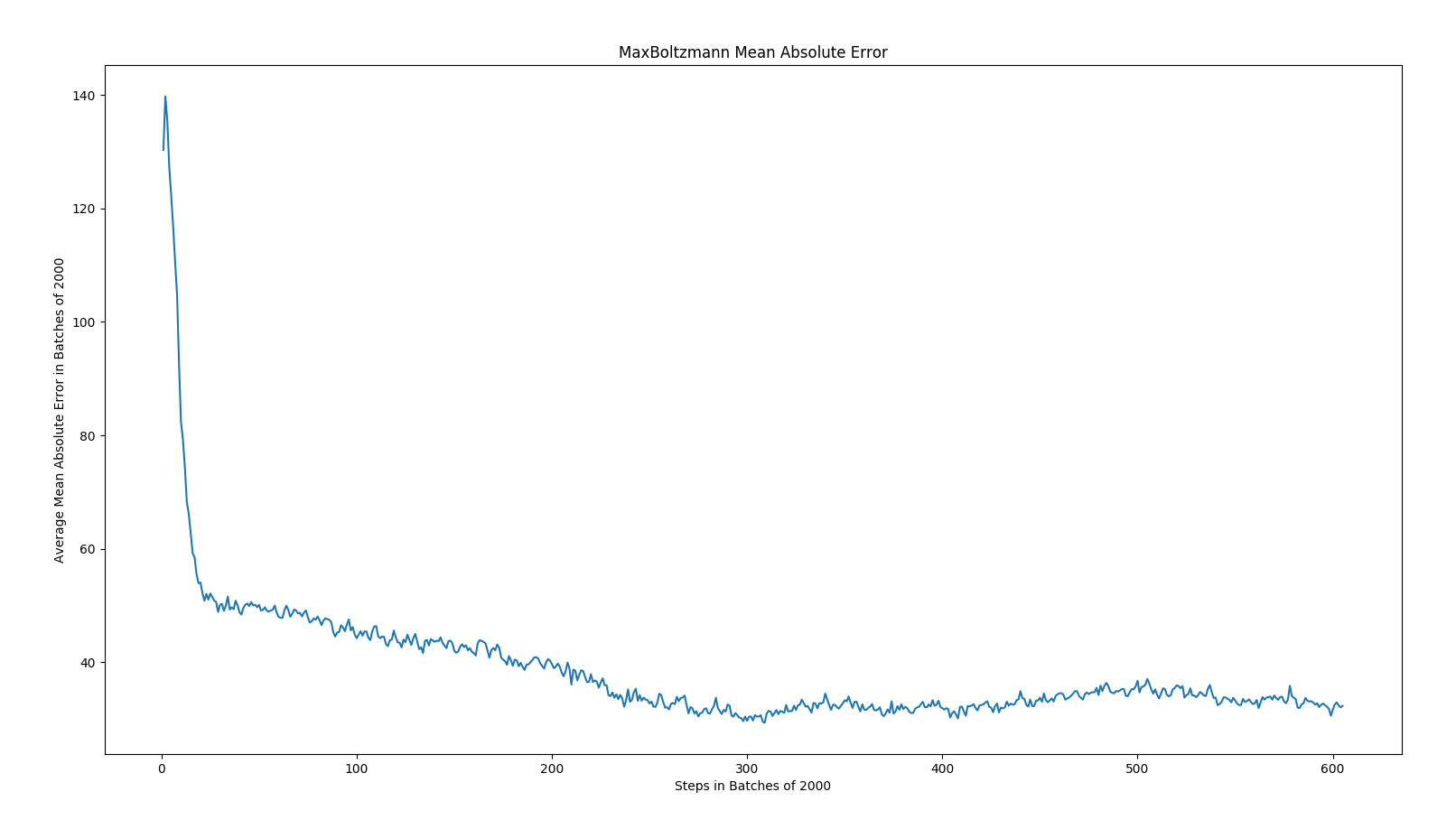
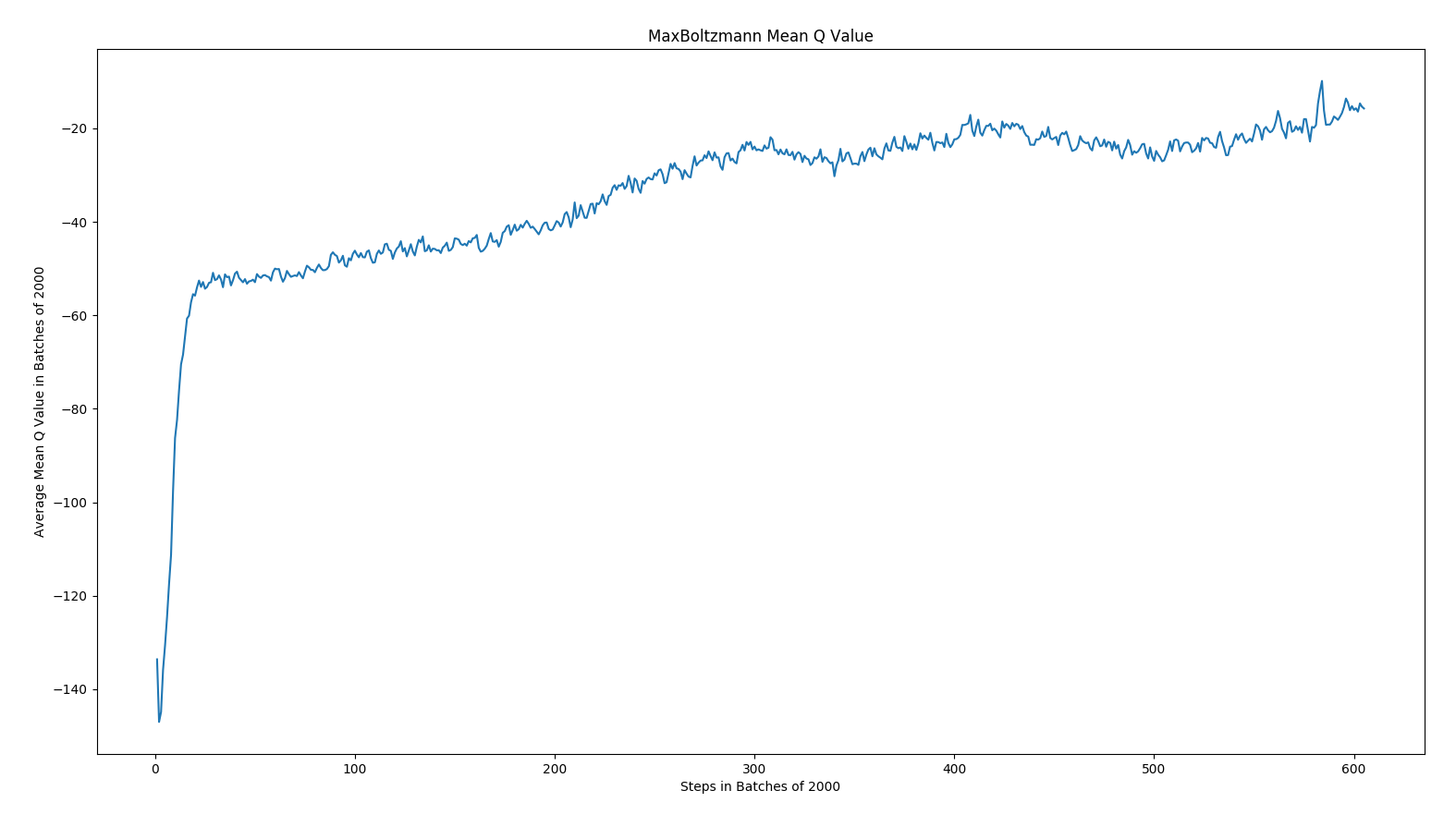
Conclusion
Overall, we managed to create a connect 4 AI that is decent. Although it will typically lose to a human player, it exhibits some intelligence in its moves and is capable of using some basic strategies to win.
One of the biggest issues of this work is our lack of self play. Since we are training the bot against a pseudo-random opponent, training was not as optimal as we would have liked. Future work would include trying a wider variety of policies and algorithms, as well as implementing a self play feature to allow the bot to play against itself.
References
[1] Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., … & Chen, Y. (2017). Mastering the game of go without human knowledge. Nature, 550(7676), 354.
[2] Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., & Riedmiller, M. (2013). Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602.
[3] Crites, R. H., & Barto, A. G. (1996). Improving elevator performance using reinforcement learning. In Advances in neural information processing systems (pp. 1017-1023).
[4] Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., … & Petersen, S. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540), 529.
[5] Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., & Riedmiller, M. (2013). Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602.
[6] Van Hasselt, H., Guez, A., & Silver, D. (2016, March). Deep reinforcement learning with double q-learning. In Thirtieth AAAI conference on artificial intelligence.
[7] Cesa-Bianchi, N., Gentile, C., Lugosi, G., & Neu, G. (2017). Boltzmann exploration done right. In Advances in Neural Information Processing Systems (pp. 6284-6293).